Concepts #
Pizza is a distributed search engine designed to efficiently index and retrieve documents across large-scale datasets. It organizes data in a hierarchical structure, allowing for flexible management and retrieval capabilities.
Before you start using Pizza, familiarize yourself with the following key concepts:
Concepts #
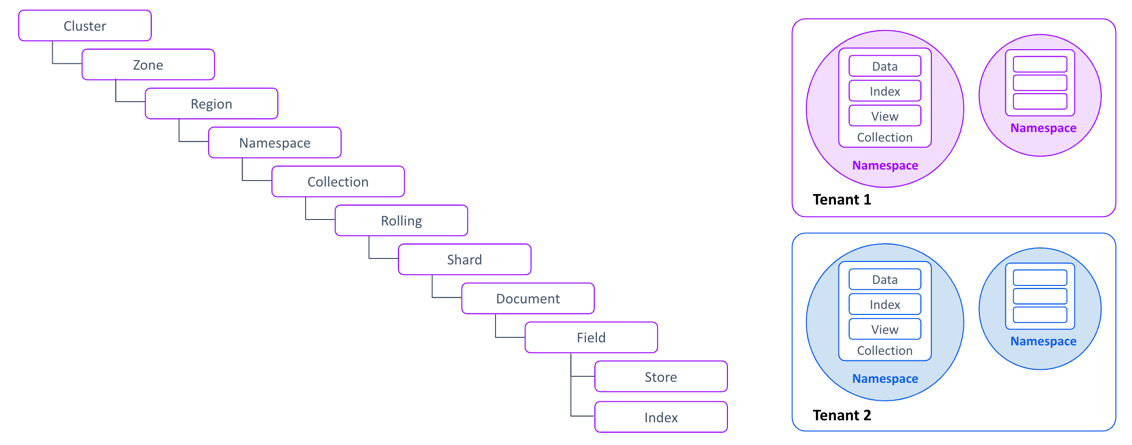
Cluster #
A cluster represents a set of interconnected nodes that collectively form the Pizza search engine. Nodes within a cluster collaborate to store and process data efficiently. Clusters can span multiple physical locations for fault tolerance and scalability.
Zone #
A zone is a logical grouping of nodes within a cluster. Zones are typically organized based on geographic proximity or network topology. They facilitate data replication and fault tolerance strategies by ensuring redundancy across different zones.
Region #
A region is a further subdivision within a zone, typically representing a smaller geographical area or a distinct network segment. Regions help optimize data access and reduce latency by distributing data closer to users or applications.
Namespace #
Pizza support multi-tenant by design. A namespace is a logical container for collections of related data. It serves as a namespace for collections, providing isolation and organization. Namespaces can be used to group data according to different criteria such as application domain, user, or data type.
Collection #
A collection is a grouping of documents with similar characteristics or attributes. Collections represent the primary unit of storage and retrieval within Pizza. Each collection is vertically partitioned into “rollings” to efficiently manage large datasets.
Rolling #
A rolling is a vertical partition of the entire collection dataset. Each rolling contains a subset of documents, with a maximum limit of 4.2 billion documents per rolling. Documents within a rolling are assigned an auto-increment sequence document ID, which is a uint32. Once a rolling is filled, the next rolling is automatically assigned, ensuring infinite scalability.
Partition #
A partition is a logical split and separation of data within a single rolling. Fixed at 256 partitions per rolling, partitions enable horizontal scalability and performance optimization by distributing data across multiple shards. Partitions are dynamically mapped to shards and can be scaled out or merged for better search performance.
Shard #
A shard is a physical container for partitions within a single rolling of a collection. Each rolling can have a different setup of shards, allowing for customized scalability and performance optimization. Shards contain partitions within a single rolling, enabling efficient data distribution and retrieval.
Document #
A document represents a unit of data indexed by the Pizza search engine. Documents can be of various types, such as text, images, or structured data. Each document contains fields that store specific attributes or properties, making it searchable and retrievable.
Field #
A field is a specific attribute or property of a document. Fields contain the actual data that is indexed and searched within documents. Examples of fields include title, content, author, date, etc.
Store #
In Pizza, the “Store” refers to the primary storage for documents, also known as forward records. By default, it utilizes Parquet for storage, with the option to integrate other external storage types in the future.
Index #
An index is a data structure used to efficiently retrieve documents based on search queries. It maps terms or keywords to the documents containing those terms, enabling fast lookup and retrieval. Indices are built and maintained based on the fields within documents.
Relationships #
Cluster to Zone/Region #
A cluster consists of one or more zones, which may further contain multiple regions. Zones and regions facilitate data replication and fault tolerance strategies within the cluster.
Namespace to Collection #
Namespaces contain one or more collections, providing a logical grouping for related data. Collections within the same namespace share common management and access policies.
Collection to Rolling #
As data within a Collection grows, it’s vertically partitioned into Rollings to manage large datasets efficiently. Rollings represent vertical partitions of a Collection’s dataset, allowing dynamic scaling and efficient querying of subsets of data.
Rolling to Partition #
Single Rolling are horizontally partitioned into 256 partitions, each containing a subset of documents. Partitions enable horizontal scalability and performance optimization within a rolling.
Partition to Shard #
Partitions are dynamically mapped to shards within a collection. Shards can scale out to multiple shards or merge back into a single shard for improved search performance and resource utilization.
Document to Field #
Documents consist of fields that store specific attributes or properties. Fields enable structured indexing and searching of documents based on their content.
Store to Index #
The store persists documents and associated metadata, while indices facilitate efficient retrieval of documents based on search queries. Stores and indices work together to provide fast and reliable data access within the Pizza search engine.