Overview #
Introduction #
INFINI Pizza is a distributed hybrid search database system. Our mission is to deliver real-time smart search experiences tailored for enterprises by fully harnessing the potential of modern hardware and the AI capability. We are committed to meeting the demands of high concurrency and high throughput in challenging environments, all while providing seamless and efficient search capabilities.
Features #
The Next-Gen Real-Time Search & AI-Native Innovation Engine Written in Rust.
Major Features of Pizza:
- True Real-Time, get search results instantly after insertion, no need to refresh anymore.
- Support partial update in place, no longer pull and push back the entire document again.
- High performance, lightning fast with high throughput and low latency, hardware reduced.
- High scalability, supports very large-scale clusters, beyond petabytes.
- Native integration with LLMs and ML, empowering AI-Native enterprise innovation.
- Design with storage and computation separation, and also storage and index separation.
Architecture #
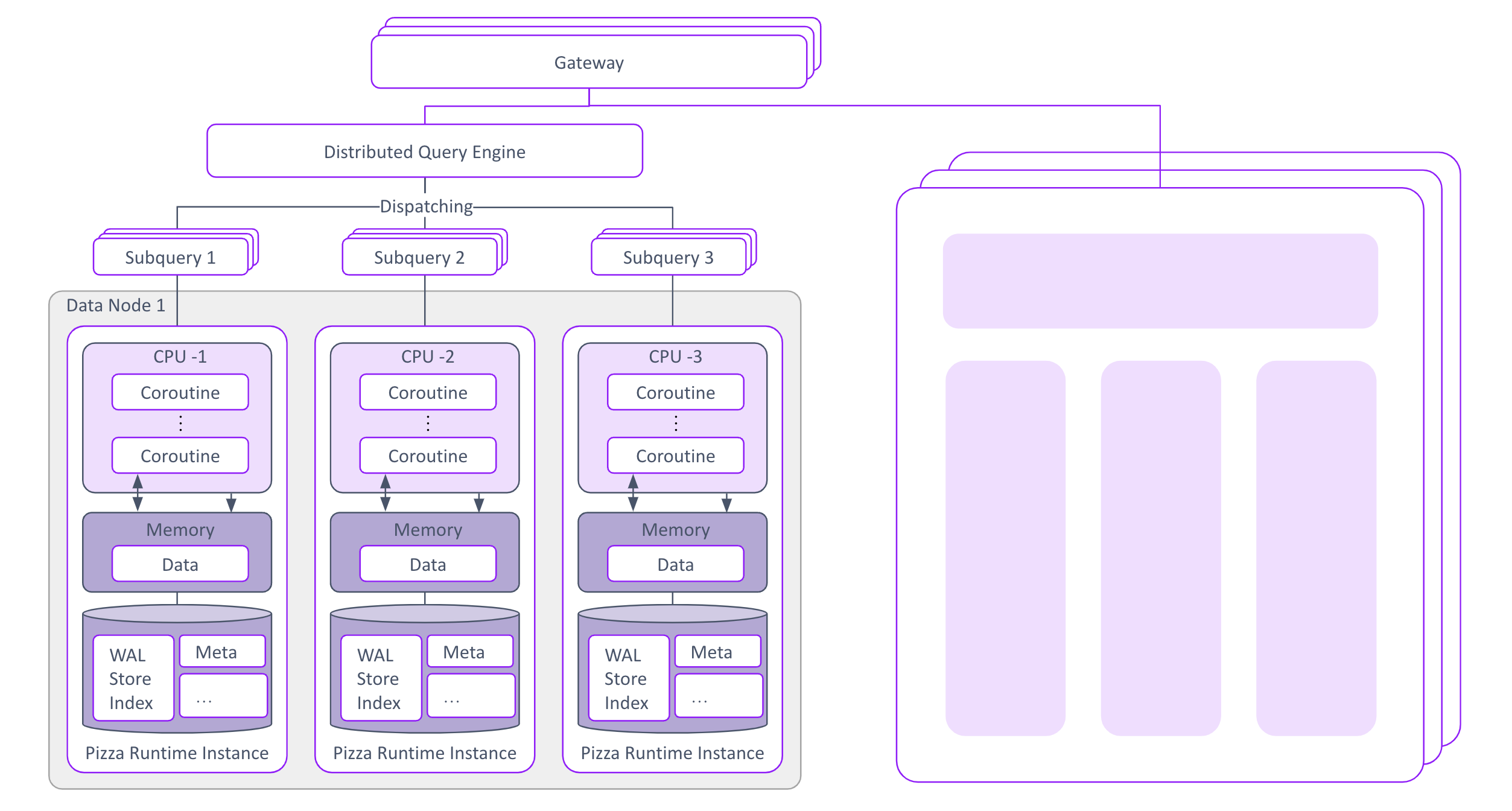
Pizza employs a share-nothing architecture, designed for modern hardware, ensuring complete isolation of resources at both the node and per-CPU level. Pizza embraces a fully asynchronous manner to access I/O and network resources, unleash the power of multiple cores, large memory and NVME SSD.
Learn more about Pizza’s architecture.
Why Pizza #
The name Pizza was taken from our unique
sharding design.
The documents in Pizza are persisted as Parquet files in object storage. Native integration with other big data systems through object storage and the standard Parquet format.
When to use Pizza #
Pizza is good fit when:
- You have latency-sensitive search applications that millisecond matters.
- You need fresh data, your data is mutable, and you need fast queries.
- You need to handle high concurrency with complex queries.
- You need to handle more than petabytes data for user-facing use cases.
- You need to handle JOIN for complex data relations.
- You need to keep thousands of fields, but only a handful are subject to change.
- You need to manage both structured and unstructured data in a cohesive manner.
Pizza is designed to address these problems at heart, to solve real critical business issues, serve your data-driven applications in realtime at very large scale. Enhance and enrich the data experiences of your end-users.
Design choices #
The philosophy of Pizza is that indices should be designed per use case, and should not attempt to fit every use case with a single index. Therefore, we introduced Views, which allow combining different document sources into a single index or separating a document into different layers of indices for different use cases.
By emphasizes the decoupling of storage and computation, as well as the separation of storage and index. Which enables efficient and scalable data processing by allowing independent management and optimization of storage resources, computational resources, and indexing strategies.
Native integration with LLMs (Language Models) and ML (Machine Learning) technologies is a key aspect of Pizza, providing powerful capabilities for AI-Native enterprise innovation. By seamlessly integrating with LLMs and ML frameworks, Pizza enables advanced natural language processing, machine learning, and data analytics directly within the search and data retrieval pipeline.
We are in the process of building the next-generation search infrastructure, driven by our unwavering commitment to delivering real-time search experiences for enterprises, unlocking the potential of modern hardware, and catering to the demands of high concurrency and high throughput in the most challenging of environments.