Why named Pizza? #
Do you wonder why this project is named Pizza?
To infinity scaling #
Pizza solves the challenge of managing massive data seamlessly. Imagine creating a collection and continuously adding documents, from zero to petabytes, without the need to worry about sharding or reindexing. Scaling your machine becomes effortless, ensuring a smooth, seamless, and painless experience for application developers.
Sharding puzzle #
One of the world’s three major challenges: What is the appropriate size for an index shard?

Shards are like cars that transport your data, but determining how many shards you need is challenging because the amount of data is unpredictable and could continuously grow.

Traditional sharding methods have several shortcomings. Currently, distributed system storage partitioning methods mainly include:
- Range-based partitioning methods require data to have a high dispersion in value ranges.
- Fixed-factor hash partitioning methods, set at database creation, may lead to over-allocation of resources if the partition factor is too large or performance issues if it’s too small.
- Consistent hashing algorithms lack adaptability to heterogeneous systems and flexibility in data partitioning, resulting in complex operations and suboptimal resource utilization.
Is there any other approach?
Pizza’s design #
Pizza does things differently!
Start with document ID #
Pizza facilitates updates, and it’s top-notch. Ensuring efficient updates requires a unique identity for each document. While accommodating a vast dataset beyond trillions of documents, one can opt for a string-based UUID or utilize a uint64 or uint128 assigned to each document. However, utilizing a wide-sized primary key may lead to resource wastage, unnecessary compression, or conversion.
In Pizza, document identification follows a two-dimensional approach. Each document is assigned a unique identity comprising
the rolling ID (rolling_id) and the internal asigned ID (seq_doc_id) within this rolling. These IDs are structured for efficiency, incorporating partition positions
for rapid data localization. Rolling IDs and assigned document IDs increment automatically. Document value ranges vary based on numeric types chosen,
accommodating trillions of documents. User-defined IDs seamlessly map to unique IDs.
With this design:
- Assigned ID format:
[rolling_id], [seq_doc_id]. - Assigned IDs adopt a composite two-dimensional structure.
- Assigned IDs are compact numeric types designed to support massive datasets.
- Assigned IDs are self-descriptive, include partition positions as routing for rapid data access.
- Rolling ID serves as metadata-level description and does not require persistence with each record.
- The space allocated for sequence assigned IDs is quite compact and compression friendly.
- Assigned ID becomes globally identity is also good fit to support frequently updates.
Within a single collection, Pizza offers varying document value ranges to accommodate different scale requirements,
For [UInt8, UInt32] the capability estimated as rolling_id ranges from 0 to 255 for UInt8 types and seq_doc_id range from 0 to 4,294,967,295 for UInt32 types.
Which can sustain [0 : 1,095,216,660,225] documents. if we scale rolling_id to use UInt16,
then it will be [0 : 65,535], [0 : 4,294,967,295] = [0 : 281,470,681,677,825], which means 281 trillions scale, should be good start for any case.
These capabilities enable Pizza to handle collections of varying sizes, from smaller-scale to trillions of documents, efficiently and smoothly scale on demand.
User-defined IDs #
“But my IDs was shipped from external database”
That’s fair, Pizza handle this simply do map the UUID to an unique assigned document ID.
For example with this document creation:
POST /my-collection/_doc/myid
{
"message": "GET /search HTTP/1.1 200 1070000",
"org": {
"id": "infini"
}
}
You will get:
{
"_key": "myid",
"_id": "0,123",
"_version": 1,
"_namespace": "default",
"_collection": "my-collection",
"result": "created",
...
}
The _id valued 0,123 means a unique Pizza document ID was assigned to myid within this collection.
Instead of passing the UUID throughout the further process, it’s common to begin with a search, and you will get a search result.
The document in the search result should contain both _id and _key. pass both of them as the document identity should work.
Just like a Pizza #
As you’ve noted, the maximum number of documents in a single rolling is a fixed size of 4,294,967,295, typically suitable for smaller use cases.
The fixed capacity of single rolling is not a bug, it is a feature!
Think of the rolling as the iron plate used for cooking the Pizza, and sending data to the rolling is akin to adding your delicious ingredients to that iron plate.
We ingest the data, we enjoy the pizza, just like that!

More Pizza - Rolling #
So you have number of documents beyond 4,294,967,295?
No worries, Let’s roll to another rolling, more rolling, more pizza, the party won’t stop tonight.
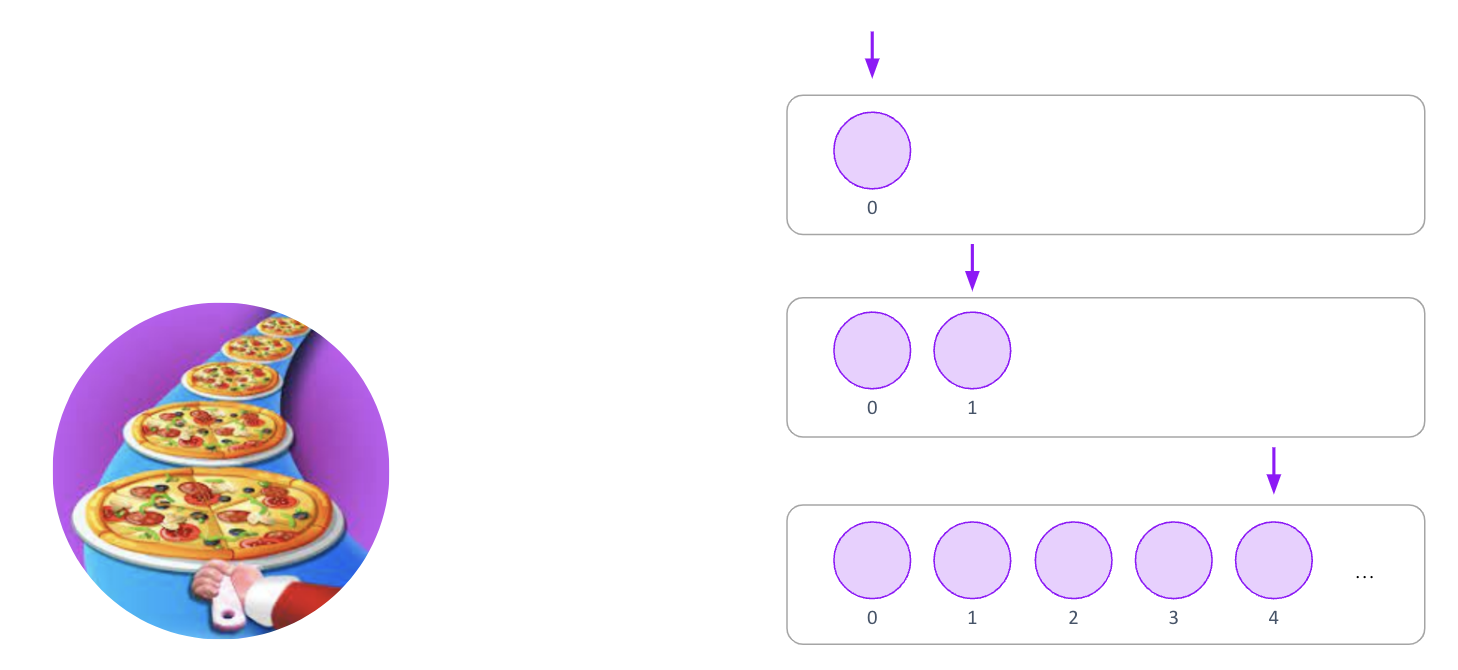
When the capacity of a rolling is exceeded, data is automatically switched to the next rolling for continued writing.
Rollings can grow infinitely to meet ongoing growth requirements.
Packaged Pizza #
There are many benefits fo package data like Pizza:
- Each rolling has a fixed size for ease of distribution and physical resource management.
- The number and size of shards are predictable.
- Shards are generated on demand, eliminating the need for advance planning.
- Scalability is infinite, allowing for horizontal expansion.
- Stable and predictable read/write performance.

Slicing with partition #
Wait, 4.2 billion is not a small number, it may choke anyway, so we introduce partitions within rolling, just like we
share slices of pizza to friends.

A single rolling can be split into a maximum of 256 physical partitions by default (configurable at creation). A lookup table is used to maintain the relationship between logical partitions and physical shards.
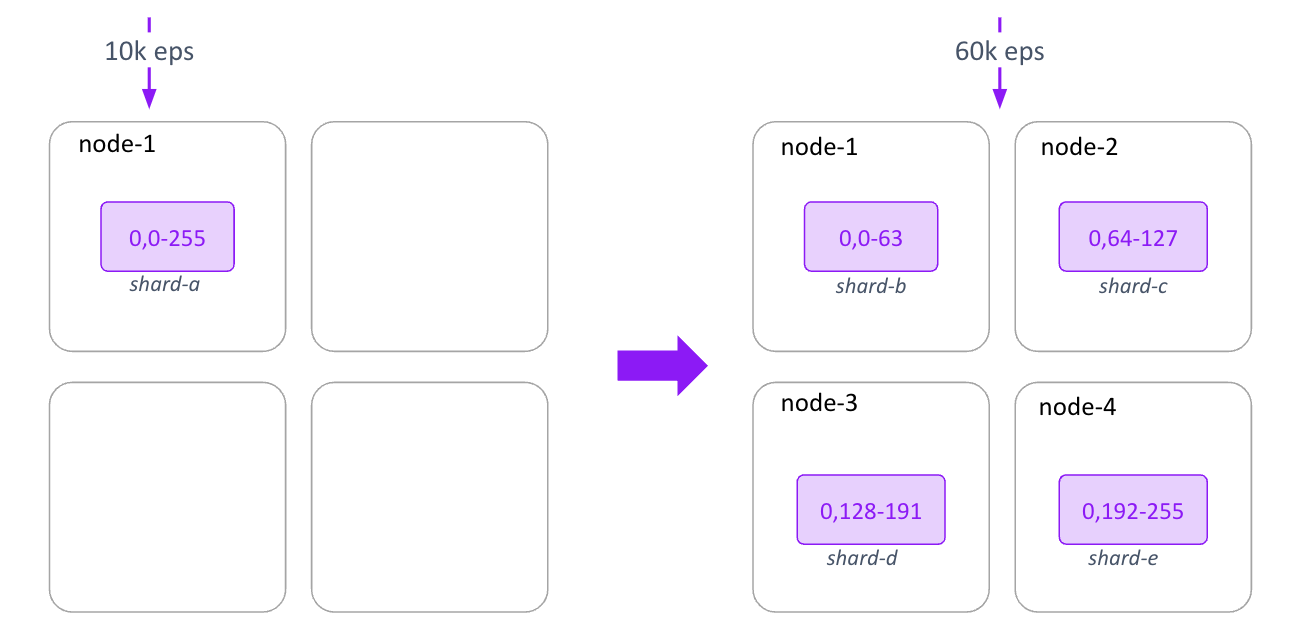
Physical shards and logical partitions can be dynamically split or merged. In scenarios with low write pressure, all partition data within a single shard is consolidated, appearing as a single data directory physically.
Hash based routing #
How about if we have more than one rolling, how do I know which rolling contains these UUID?
Custom or assigned IDs are hashed based to establish a one-to-one relationship with partitions:
[HASH(KEY) or ID] % 256 = PARTITION_ID

The worst case is the request need to revisit same partition across all rollings, but the scope is limited as stepped with 4.2b, also we can have UUID mapping cache ahead.
Always better to use Pizza assigned _id rather the _key for mutation, as _rolling_id is part of _id, so Pizza know which _rolling need to talk without ask.
Ultimate scaling #
Lastly, we will talk about replica, each shard can have replicas, to scale out for more search throughput.
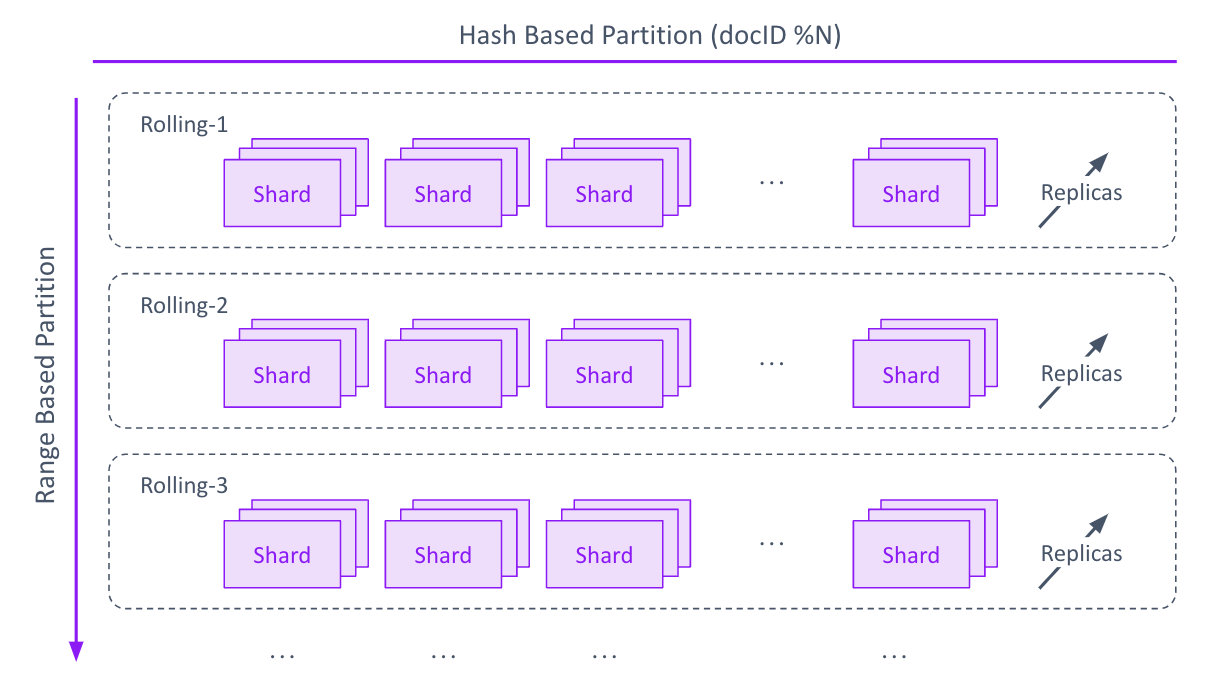
Rolling, Partition, Replica - three dimensions for ultimate scaling.
The more data you feed in, the more pizza you cook. Enjoy your yummy data!